Decision Trees: an overview for classification problems


If you've ever made a decision you've unconsciously used the structure of a decision tree. Here's an example: You want to decide whether you are going to go for a run tomorrow: yes or no. If it is sunny out, and your running shorts are clean, and you don't have a headache when you wake up, you will go for a run.
The next morning you wake up. No headache, running shorts are clean, but it's raining, so you decide not to go for a run.
But if you had answered yes to all three questions, then you would be going for a run.
You can use a flow chart to represent this thought process.
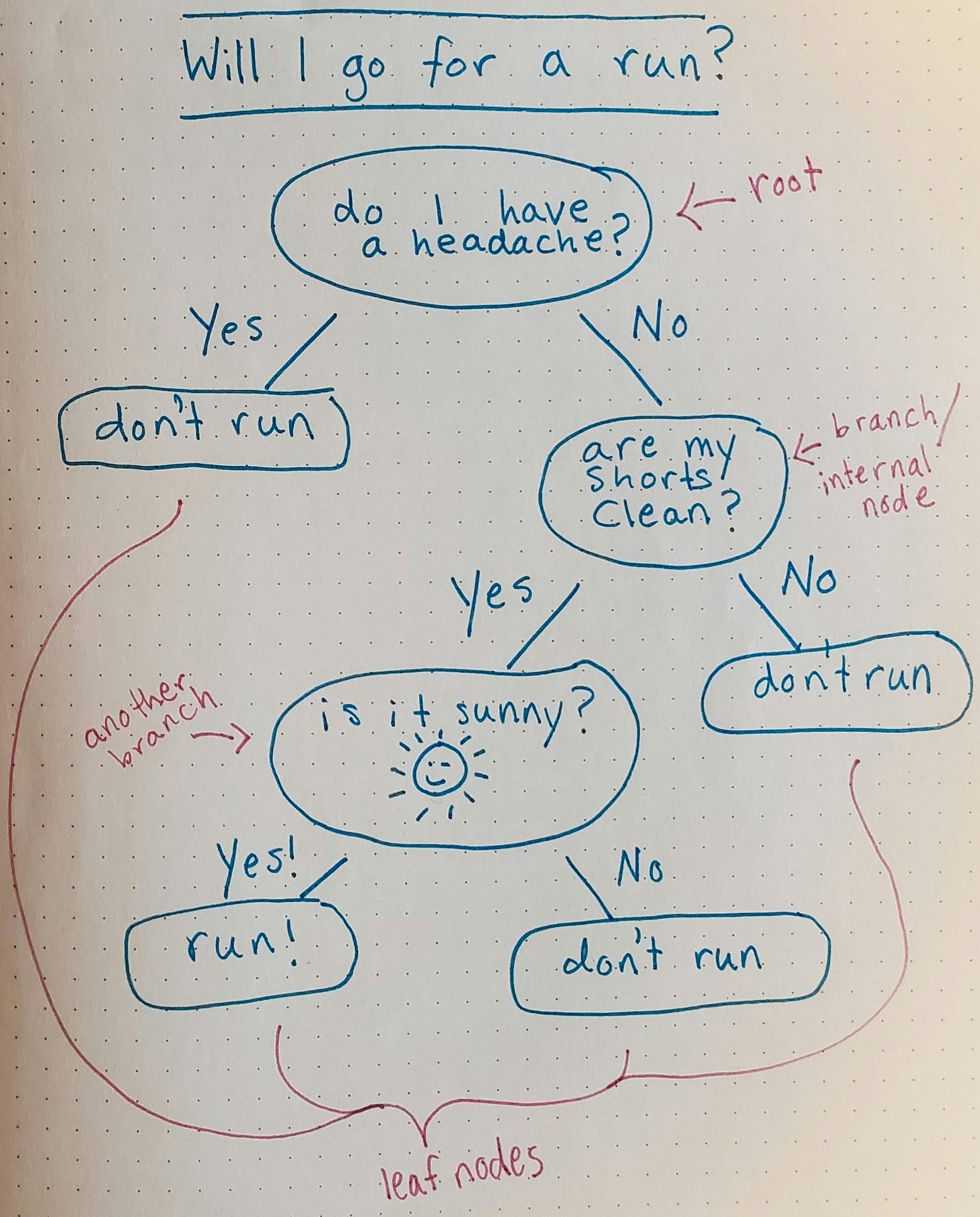
That flow chart is a simple decision tree. Follow the answers and you will reach the conclusion about whether you will run or not tomorrow.
Decision trees in machine learning
We can teach a computer to follow this process. We want the computer to categorize some data by asking a series of questions that will progressively divide the data into smaller and smaller portions.
We will get the computer to:
- Ask a yes or no question of all the data...
- ...which splits the data into 2 portions based on answer
- Ask each of those portions a yes or no question...
- ...which splits each of those portions into 2 more portions (now there are 4 portions of data)
- Continue this process until...
- All the data is divided
- Or we tell it to stop
This is an algorithm, and it is called recursive binary splitting. Recursive means it's a process that is repeated again and again. Binary means there are 2 outcomes: yes or no / 0 or 1. And splitting is what we call dividing the data into 2 portions, or as they're more fancily known, splits.
How does the algorithm decide which way to split up the data? It uses a cost function and tries to reduce the cost. Whichever split reduces the cost the most will be the split that the algorithm chooses.
What is reducing the cost? Briefly, cost is a measure of how wrong an answer is. In a decision tree, we are trying to gain as much information as possible, so a split that reduces the cost is one which will group similar data into similar classes. For example, say you are trying to sort a basket of socks based on if they are red or blue. A bad split would be to divide the basket of socks in half but keep the same ratio of red and blue socks. A good split would be to put all the red socks in one pile and all the blue socks in another. (A decision tree algorithm uses entropy to measure the cost of each split, but that discussion is beyond the scope of this article.)
We can use decision trees in classification problems (predicting whether or not an item belongs to a certain group or not) or regression problems (predicting a discrete value).
Using these answers to categorize new data instances
Then when we have some new data, we compare the features of the new data to the features of the old data. Whichever split a given sample from the new data matches up with, is the category that it belongs to.
- a given test sample belongs to the split where the training samples had the same set of features as that test sample
- For Classification problems: at the end the prediction is 0 or 1, whether the item belongs to a class
- For Regression problems:
- We assign a prediction value to each group (instead of a class)
- The prediction value is the target mean of the items in the group
Now let's discuss the data
Now let's look at an actual dataset so we can see how a decision tree could be useful in machine learning.
If mushrooms grew on trees...
We're going to look at the mushrooms dataset from Kaggle. We have over 8,000 examples of mushrooms, with information about their physical appearance, color, and habitat arranged in a table. About half of the samples are poisonous and about half of the samples are edible.
Our goal will be to predict, given an individual mushroom's features, if that mushroom is edible or poisonous. This makes it a binary classification problem, since we are sorting the data into 2 categories, or classes.
By the way, I don't recommend you use the model we produce to actually decide whether or not to eat a mushroom in the wild.
Check out the code
Here, you can find a Kaggle Notebook to go along with the example discussed in this article. I provided a complete walkthrough of importing the necessary libraries, loading the data, splitting it up into training and test sets, and making a decision tree classifier with the scikit-learn library.
How do we know when to stop splitting the data?
At a certain point you have to stop dividing the data up further. This will naturally happen when you run out of data to divide. But that would be after we have a massive tree of over 8,000 leaf nodes - one for each sample in our training data! That would not be very useful, because we want to have a tree that generalizes well to new data. If we wait too long and let our algorithm split the data into too many nodes, it will overfit. This means it will understand the relationships between features and labels in the training data really well - too well - and it won't be able to predict the class of new data samples that we ask the model about.
Some criteria for stopping the tree:
- Setting the max depth: tell the algorithm to stop dividing the data when it gets to a certain number of nodes
- Setting the minimum number of samples required to be at a leaf node
- Setting the minimum number of samples required to split an internal node
- this is helpful if we want to avoid having a split for just a few samples, since this would not be representative of the data as a whole
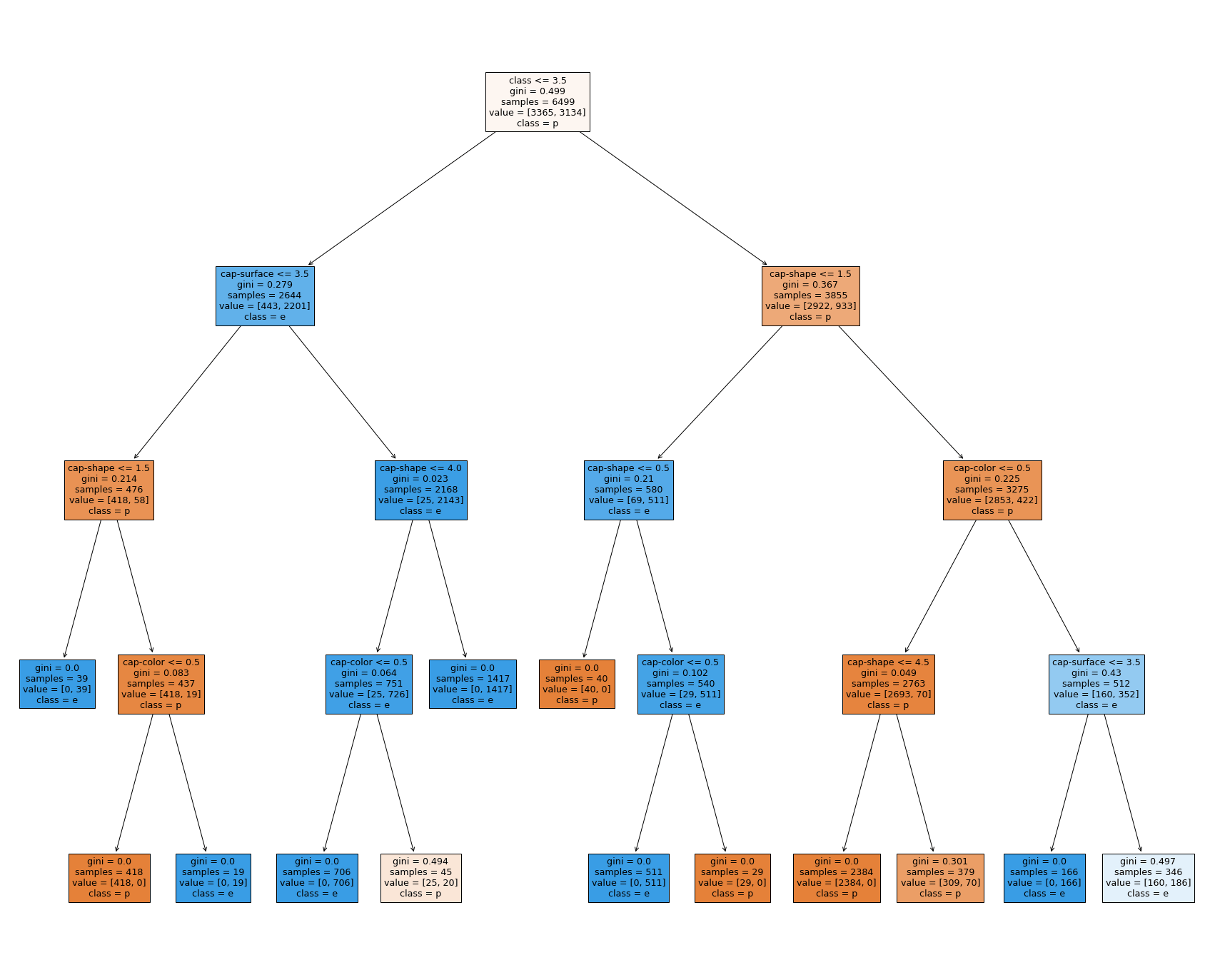
For example, here is how we can set the max depth with sklearn's library:
from sklearn import DecisionTreeClassifier
model_shallow = DecisionTreeClassifier(max_depth=4, random_state=42)
model_shallow.fit(X_train, y_train)
This will yield a tree that only has 4 decision nodes total.
What are the drawbacks of decision trees?
A decision tree algorithm is a type of greedy algorithm, which means that it wants to reduce the cost as much as possible each time it makes a split. It chooses the locally optimal solution at each step.
This means the decision tree may not find the globally optimal solution--the solution that is best for the data as a whole. This means that at each point where it needs to answer the question "is this the best possible split for the data?" it answers that question for that one node, at that one point in time.
This means that the decision tree will learn the relationship between features and targets in the training data really well but it won't generalize well to new data. This is called overfitting.
One way we can deal with this overfitting is to use a Random Forest, instead of a Decision Tree. A Random Forest takes a bunch of decision trees and then uses the average prediction from all of the trees to predict the class of a given sample.
What are the benefits of decision trees?
Decision trees are fairly easy to visualize and understand. We say that they are explainable, because we can see how the decision process works, step by step. This is helpful if we want to understand which features are important and which are not. We can use the decision tree as a step in developing a more complicated model, or on its own. For example, we can use feature_importances_ to decide which features we can safely trim from our model without it performing worse.
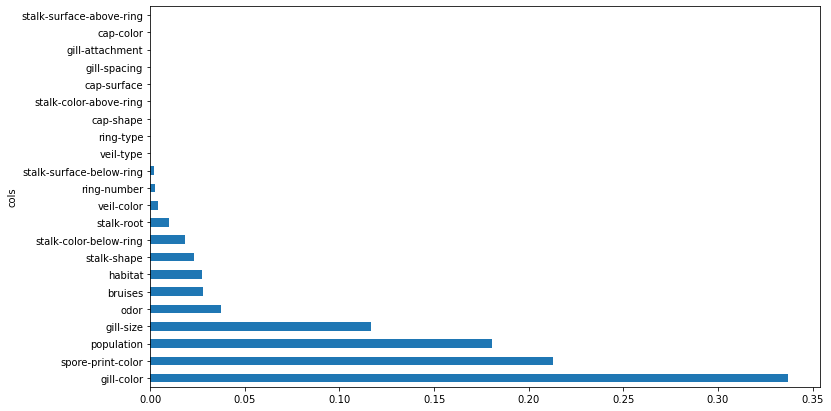
A Decision Tree is an excellent starting point for a classification problem, since it will not just give you predictions, but help you understand your data better. As such, it is a good choice for your baseline.
Terms cheat-sheet
Decision Tree Anatomy:
- node: the parts of the tree that ask the questions
- root: the first node--creates the initial split of data into 2 portions
- branches or edges: internal nodes--they come between the root node and the leaf nodes
- decision node or leaf node: when we reach the end of a sequence of questions, this is the node that gives the final answer (for example, of what class a sample belongs to)
- split: the portion of data that results from splitting
Other terms:
- training data: the data used to fit the model
- validation data: data used to fine-tune the model and make it better (we left out that step in the Kaggle notebook)
- testing data: the data used to test if the model predicts well on new information
- instance / sample: one example from a portion of your data - for example, a single mushroom
- algorithm: step by step instructions that we give to a computer to accomplish some task
- baseline: a simple model we train at the beginning stages of exploring our data to gain insights for improving our predictions later on (all future models will be compared to this one)
If you enjoyed this article, please take a look at the Kaggle notebook that I made to go with it. It is a beginner friendly example of using the Mushrooms dataset to build a decision tree, evaluate it, and then experiment a bit with the model.
Additionally, I'd love to get feedback about the format of breaking the general overview of a topic apart from the code notebook. I felt that both could stand on their own, so someone could go through the code example to see how it works, or someone could read this article. If you want to read both, hey that's cool too!
Thank you for reading!