

Why improve on Decision Trees?
At the end of my article on Decision Trees we looked at some drawbacks to decision trees. One of them was that they have a tendency to overfit on the training data. Overfitting means the tree learns what features classify the training data very well, but isn't so good at making generalizations that accurately predict the testing set.
I mentioned that one way we can try to solve the problem of overfitting is by using a Random Forest. Random Forests are an ensemble learning method, so called because they involve combining more than one model into an ensemble. Essentially, we are going to train a bunch of decision trees, and take the majority vote on class predictions for the test data.
Quick reminder:
Training data is the subset of your data that you use to train your model. The tree in the random forest will use this data to learn which features are likely to explain which class a given data sample belongs to.
Test data is the subset of your data that you use to make sure your model is predicting properly. It's supposed to simulate the kind of data your model would make predictions on in the real world (for example, if you are making a dog breed classifying app, the test data should mimic the kinds of images you might get from app users, uploading pictures of dogs).
Wisdom in a crowd
Have you ever been in a classroom and the teacher for some reason asks the class as a whole a question. (Not necessarily a great teaching technique, but let's move on.) You think you know the answer, but you are afraid of being wrong, so you wait a little while until bolder classmates have given their answers before agreeing with what the majority is saying.

This can be a good strategy, if not for learning the material, at least for being right. You wait to see what the consensus is in the classroom before casting your vote.
You're not sure of your answer, but if enough other people agree with you, it seems more likely to you that your answer is the right one.
While this technique isn't probably the best predictor of whether a group of students is learning the material, it can be used to good effect in machine learning.
How do Random Forests work?
Building a random forest classifier can be broken into two steps.
- Training, by building a forest of a bunch of different trees, all of which learn from a bagged random sample of the data **
- Making an predictions by taking the predictions of each tree in the forest and taking the majority vote of which class each sample in the test set belongs to
To train a Random Forest, we train each decision tree on random groups of the training data, using a technique called bagging or bootstrap aggregating.
What actually is bagging?
Bagging is not dividing the training data into subsets and building a tree from each subset.
Instead, each individual tree randomly grabs samples from the training set.The training set has n number of samples. What the tree does is choose n number of samples randomly from a bag of all the training samples, but after considering each sample it will put it back into the bag before picking out another one. This is called sampling with replacement.
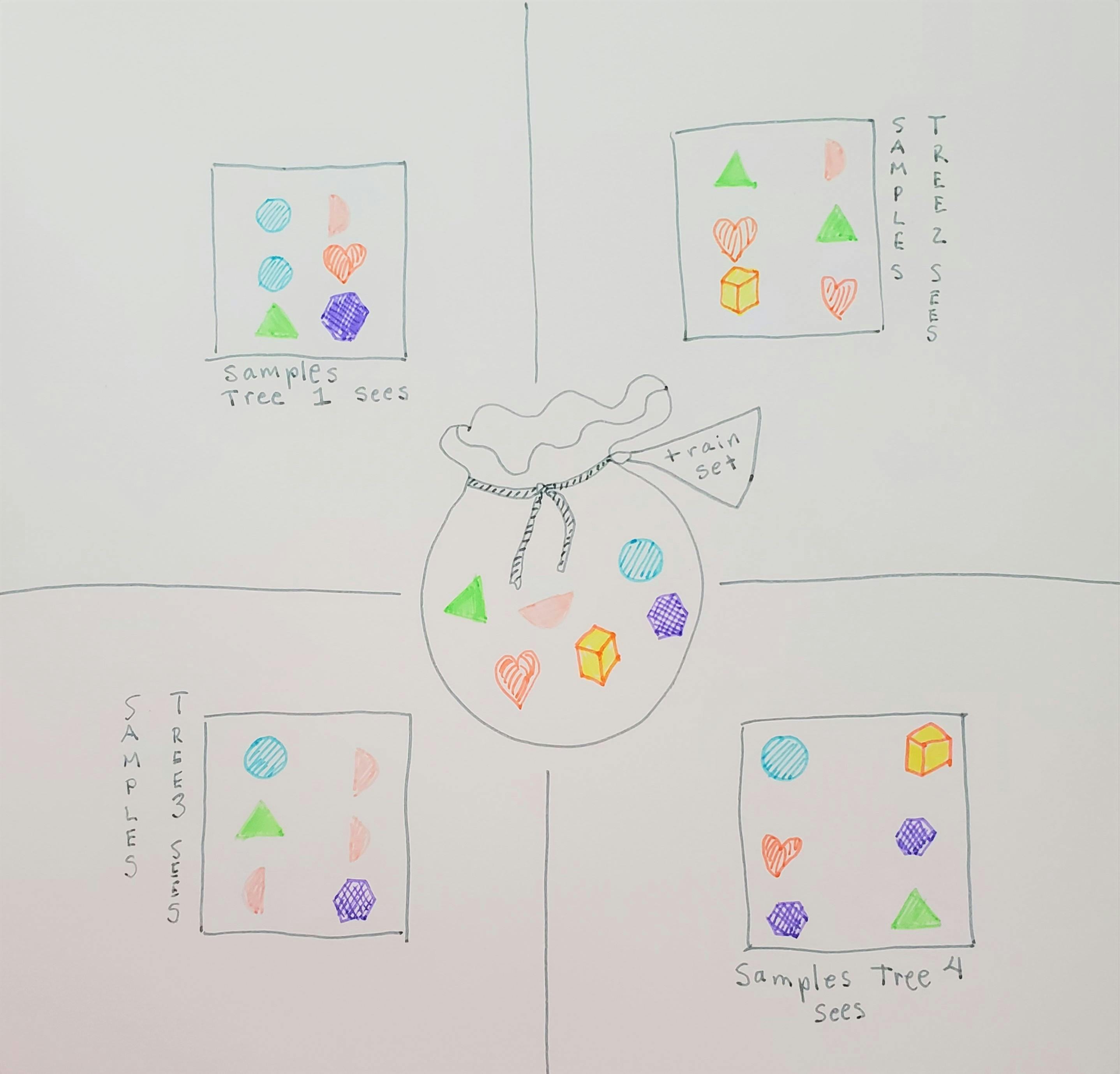
In this very simplified image the different shapes and colors in the bag just represent different samples in the training data (there is no significance intended to the shapes and colors). Each tree grabs a sample from the bag and then puts it back before grabbing another sample, so each tree ends up with a different set of data that it uses to build its tree.
Note that this does mean that any given tree in the random forest might end up with the same sample more than once (as you can see in my little picture). But because there are multiple trees in the forest, and each one chooses samples randomly, there will be enough variation in the trees that it won't really matter too much if samples are repeated for a given tree.
Prediction time
Once the trees are made they can make their predictions. We feed the test set to the trees in our random forest classifier, each tree makes its predictions on the test set, and then we compare the predictions and take the ones that the majority of trees agrees on.

The benefits of Random Forests
Like decision trees, random forests are straightforward and explainable. Since a random forest is made up of decision trees, we still have access to the Feature Importance (using Scikit-Learn, for example) for understanding the model. Our model can still tell us how important a given feature is in predicting the class of any sample.
Since we are getting the answer from more than one tree, we are able to get an answer that the majority agrees upon. This helps reduce the overfitting we see in a Decision Tree. Each tree in the random forest is searching for the best feature in a random subset of the data, rather than the best feature in all of the training set. This helps the model achieve more stable predictions. The Random Forest Classifier as an ensemble can't memorize the training data, because each tree in the forest doesn't have access to all the training data when it makes its tree.
Bonus: Hyperparameters in Scikit-Learn
Hyperparameters is a term used in machine learning to refer to the details of the model that you can tweak to improve its predictive power. These are different from parameters which are the actually things that your model uses to compute functions (like the weights w and the bias b in a linear function).
Some hyperparameters you can tweak in Random Forests are:
- The number of trees—in sklearn (Scikit-Learn's machine learning library) this hyperparameter is called
n_estimators- more trees generally improves the model's predictive power, but also slows down training the model, because there are more trees to build
- The
n_jobshyperparameter in sklearn tells your computer how many processors to use at once, so if you want to have the model run faster, you can set this hyperparameter to-1, which tells the computer to use as many processors as it has
Other hyperparameters that you can change are the same ones found in Decision Trees—for example, max_features and min_samples_leaf —which I discussed in my post and demonstrated in this Kaggle notebook on Decision Trees.
In conclusion
Random Forests are a handy boost to your baseline Decision Tree model, either in classification or regression problems. You can usually reduce overfitting, while not giving up too much of the model explainability that you have access to with a Decision Tree algorithm.